Opsification of the Corporate World
Ops as a Suffix
The success of the DevOps industry has led to spread of DevOps methodologies to many aspects of the corporate world.
In the past 10 years of DevOps we’ve seen the rise of:
FinOps
GitOps
DataOps
ChatOps
CloudOps
MLOps
DevSecOps
DevSecNetOps
And more recently:
LLM Ops
I’m going to dive into what key trademarks made DevOps so successful and how we can expand these philosophies to other business practices.
Let’s start with the first graph that everyone being introduced to DevOps sees: the infinity loop. It represents the agile implementation of making small incremental changes that are built, tested, released, monitored and improved based on feedback from the previous steps.
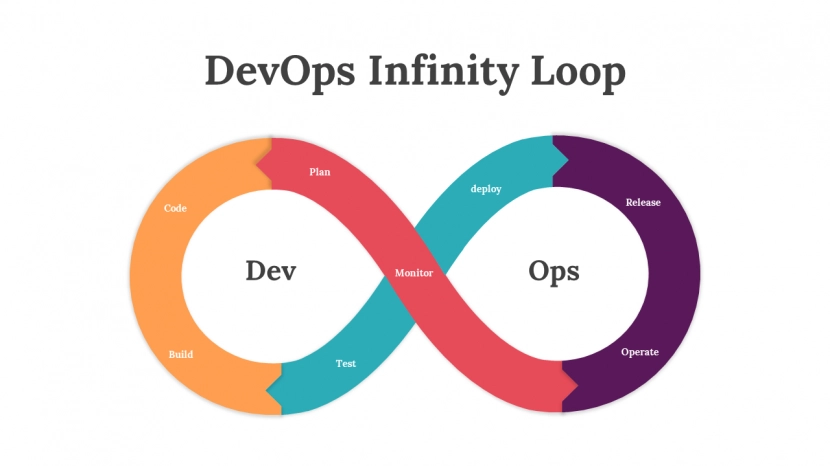
DevOps is often thought of as a highly technical field which has previously scared many from approaching it as a career previously. While there are many important technologies to master that will make you a successful engineer. That isn’t required to be successful at DevOps. In DevOps you need to master an incremental approach to making changes. Your solutions should help make changes for teams quicker, safer, and include more cross-team collaboration. The end result is a better product whether that is in development space, financial space, data, security, or other areas.
The success of DevOps comes down to two components: the goals and the processes.
My personal take on the goals of DevOps includes (there are probably an abundance of other ideologies that can be included.)
- Quicker changes.
- Implement Guardrails
- Inject cross-functional collaboration
The processes to achieve DevOps is the next step. A DevOps process will contain the following elements
- Pipelines and automations.
- Metrics
- Mechanisms for cross-team collaboration
- Infrastructure-as-Code
Touching on each of these processes a bit more, I want to give a train analogy. The pipeline is going to be the bedrock of the whole process. Without it we can’t organize our workflows and include all the tools we will need to continually drive improvements.
Pipelines and Automations
In this train analogy let’s call the tracks the pipeline. It’s a predetermined path for all of us to follow. We have stops, checks, systems, and procedures to follow for each trip along this path for it to be a success. We can think of automations as the stops at various train stations along our route. At each stop we can perform various tasks like using the restroom, buying snacks, or switching seats. The automations in DevOps should ideally be determined by the pipeline and run when we get to our stops. Also in DevOps the goal for the automations is to not involve humans. If we are releasing software. We may want the code tested as soon as it finishes building. From there we may want it deployed as soon as it finishes automated testing. If we inject humans into these automations we can see how it would slow down the train substantially. If the software has to be tested by humans we have to wait for QA Engineer to be available and then run through manual checks. Fingers crossed they didn’t miss anything on the checklist. After these interruptions which could take hours to days, they may finally allow the train to continue to the next stop. So do your best to have your pipeline run without human interruptions.
Metrics
Next is metrics. As pedestrians we often don’t have any insights into the command center for trains. But a lot of data is collected to make decisions. The metrics on a rail system prevent train cars from hitting each other or going too fast around turns as well as optimize the whole track to get as much traffic across the tracks as possible.

Same goes for DevOps metrics. We need to be able to measure ourselves so we can find bottlenecks and make improvements. Ideally we are measuring two things. We should measure the key results of the system we are building the pipeline for. For software we often want to know that software is stable and we aren’t introducing bugs, performance is also often measured. If a piece of software is too slow users likely won’t have a great experience. The second thing we should be measuring is the success of the pipeline itself. These “meta” insights can help us make sure we are serving the business practices most efficiently. A key metric I like to use and many of my peers have used in the past is Cycle Time. Here we measure the amount of time it takes from the beginning of the pipeline to the end of the pipeline. In the software world, this generally is measured as the time a developer commits code to a repository until that code is in production available to customers. We can measure many elements of the pipeline itself too. Some examples are cost, failures rate, adoption rate, etc.
Cross-team Collaboration
The next step may seem redundant: cross-team collaboration. It is both a goal and a crucial process on our journey. In our train example, all the automations or “train stops” are performing various tasks. These tasks may be run by our team, but they could also be run or instructed by another team. The goal is allow other teams to build their train station on your path so they don’t have to stop the whole train mid journey. In DevOps it is very common for security teams to have steps in the pipeline to run security checks. For example if you are building a server from a code based solution. Security can run an automated check to make sure your server is not going to be open to the internet before you even build the server! This allows as many teams to come in and build their automations without having to create bottlenecks in the process. Any number of teams can now have input on the train's journey without sacrificing speed or quality. Additionally, by ensuring it is part of the process, we can get instantaneous feedback as well as checks can be run prior to any changes going live. This is a huge improvement especially in the security world. If we evaluate infrastructure or code after it goes live and a vulnerability is found, we expose the company to unnecessary risk when many of these tasks can be done the moment code is first committed.
Infrastructure-as-Code
The last piece of the process is Infrastructure-as-Code. At the simplest form all changes are stored in text format so their history can be reviewed. Any team member should be able to know what changed and when and if needed, they should be able to revert back to an earlier version. This is done with Infrastructure-as-Code or IaC. To show what is IaC, let’s first understand what isn’t IaC. When you change the volume on your phone, you are manually making a change for which you won’t have the history saved of that change. In one day you won’t be able to answer how many times you changed the volume, when you changed the volume, or what the previous volume was before. Compare this to Google Docs. It does save all this information. You can get time stamps, see what changed, and if necessary revert to previous versions. In DevOps the tools you would use are version control and a code/configuration management system. Examples would be Git (Github) and Terraform (a config format). If you are not familiar with Terraform we can use the Google Doc example where you can save a file as a .docx format or save it as a .pdf. A standard that is understandable by other systems that can be shared and edited by other users.
We should now understand what makes DevOps successful. DevOps has used these practices to improve many aspects of development. But this blog isn’t about DevOps. It’s just the first and most recognizable implementation which helps ground the conversation. This blog is about these steps and how they can help many other aspects of business practices. I don’t know what to call the practice of these methodologies as a whole anymore. Clearly DevOps isn’t the right term as the scope has grown so much in the past 10 years. I’m in between calling it *Ops (StarOps), Opsification, or the Ops Framework. If any of these speak to you or if you’ve heard another term that describes this phenomenon, please ping me on LinkedIn.
How to Spread *Ops Methodologies?
How do we spot opportunities within our companies? There are four trademarks of business units that can benefit from *Ops principles.
- Repetitive tasks
- Communication heavy workflows
- Difficulty working across teams and business units
- Business unit not scaling efficiently with the company growth
Using these trademarks, we can apply the tools we learned to compliance and governance. It’s traditionally been a very repetitive non-automated business practice that could use a little Opsification. Let’s walk through an example. Compliance Director Joe, every quarter runs through his checklist of controls that his company states they follow in order to achieve various certifications like SOC2 or PCI. Joe and his two direct reports go through all 210 controls each quarter to validate they are adhering to their policies. Then with these reports once per year they will submit their findings to auditors to maintain their compliance.
This meets item 1: Repetitive work.
Also will meet item 2: A lot of the compliance controls can be interpreted differently from person to person. There is a lot of opportunity for language and communication to cause some breakdowns in the process.
Also meets item 3: To pull all controls they will have to work with potentially a dozen different teams to ensure each team is following the procedures and gather this evidence from their systems.
This example probably doesn't match item 4: Compliance controls shouldn’t change much from audit to audit and the number of teams they work with won’t change too much as well.
So three out of four definitely feels like there would be opportunities to Opsify the business practice.
We know our goals
- Quicker changes.
- Implement Guardrails
- Inject cross-functional collaboration
What pipelines, automations, and metrics can we include to help Joe and his team out? First item I can think of is guardrails. A common control is user access. If all user access is provisioned and deprovisioned automatically, explaining the control and providing evidence is easier to answer. An email of an automated system provisioning and deprovisioning users based on certain requirements could be shared with Joe’s team automatically and submitted for evidence during their audits.
Another process element is metrics. A great metric to follow in this example is control coverage. How many controls are fully automated on both the implementation and evidence collection. Using the user example again. If no humans have access to create users on X system then by default they must be following their policies. Implementation would be complete. Next is the evidence to that claim. That could be a generated report as part of the pipeline that lists all users that have not been created by the pipeline. If the pipeline tags users with a piece of metadata we can follow and ensure only users we’ve identified as needing access have access.
Lastly, a tool that I think could help Joe and his compliance team is Infrastructure-as-Code. Again using the user example a company policy should state who should have access to production systems. If an automated system is provisioning and deprovisioning users it is following a set of logic. If this logic is code multiple users can read it and ensure it is doing exactly what our policy dictates. Compare this to a human user manually creating users. Often, if someone that shouldn’t have access complains loud enough, a human will relent and give access. The fact that the algorithm that determines access is in code allows more confidence in the system that the users who have access should have access.
I’m going to wrap it up here. What everyone should take away from this post is what the methodologies that made DevOps successful are. How have those methodologies been broken down and used for other business practices? And lastly how can we determine if there is an opportunity to Opsify other business practices and what our
train of thought should be? (train pun intended)
